I’ve recently started using RSS again, with a couple of goals in mind.
- to read the latest interesting blog posts in a more focussed way
- to assist with personal research, and that’s what this post is about
Internet Archive
You can set up an RSS feed for any search using their Advanced Search page:
- scroll half way down to “Advanced Search returning JSON, XML, and more”
- enter your Query (default sort is newest first)
- choose: RSS format
- press Search
You should be prompted to add the feed to your default RSS reader.
I use this to track searches for items that match my hobby interests:
- Hanafuda
- Classic Macintosh software
- Japanese magazine scans
- Authors
- Publishers
Every time a new item appears in my RSS reader it feels like Christmas!
Thanks to the generosity of the Internet Archive there is no limit to the number of RSS feeds you can generate.
Yahoo! Japan Auctions
Sadly, Yahoo! no longer provides RSS feeds for their Auctions website.
But where there is a will, and technology, there is a way. We can use a website called PolitePol to generate RSS feeds! It works on any website, especially those with generated/structured content. A search results page is perfect.
PolitePol offers a free account with certain limits. At the time of writing those are: max 20 feeds, no RSS images (more on that later), and no support for websites that require scripting to load their content (so I can’t do this with Mercari), and hourly refresh. You can pay to unlock those restrictions, but I’ve not yet found a need to do so. PolitePol is also Open Source so you can host it yourself - as easy as launching a Docker container.
Example usage
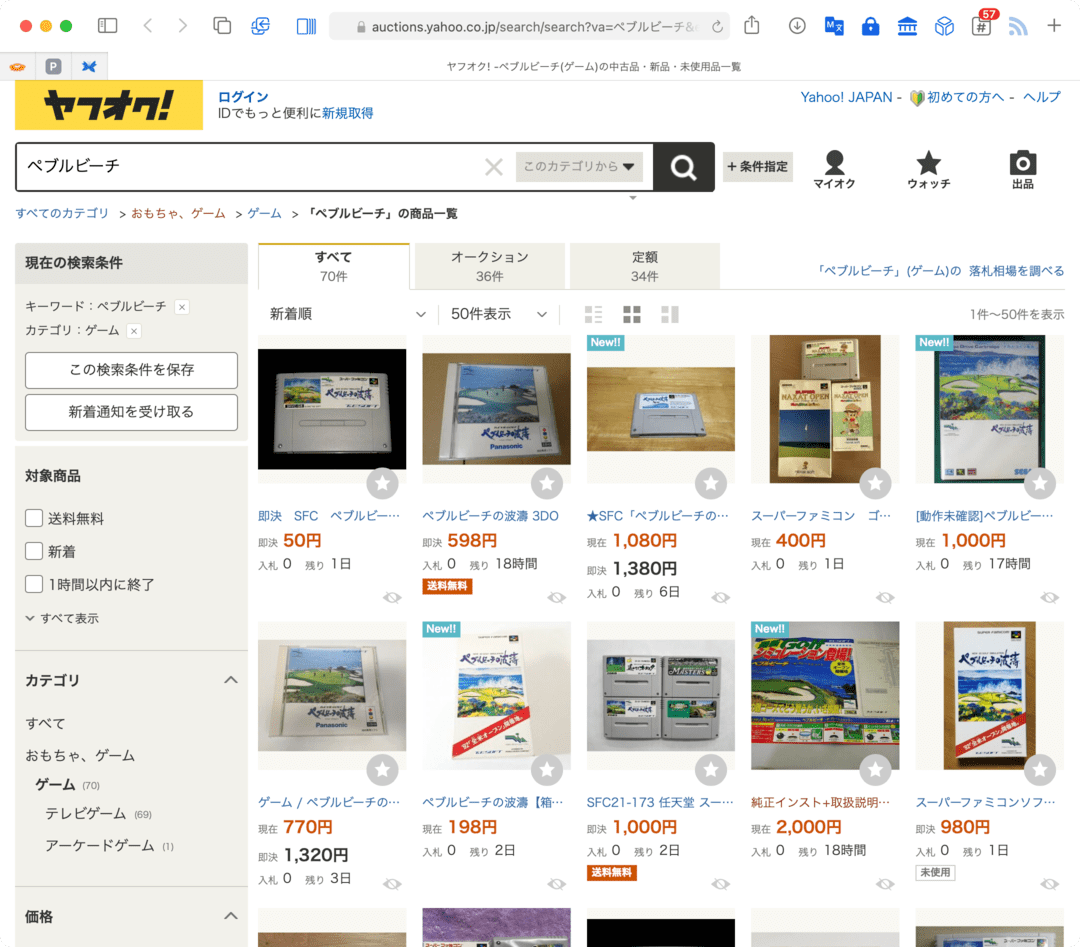
The first thing we need to do is craft a Yahoo! Japan Auctions URL that makes sense so that we can paste it into PolitePol.
- I’ll search for ペブルビーチ (Pebble Beach)
- The default sort order is おすすめ順 (Recommended) but we need to set it to 新着順 (Newest)
- We’ll limit the search to specific categories: おもちゃ、ゲーム (Toys & Games) followed by ゲーム (Games)
This gives us the following URL (which could be trimmed down manually but we’ll use it as-is):
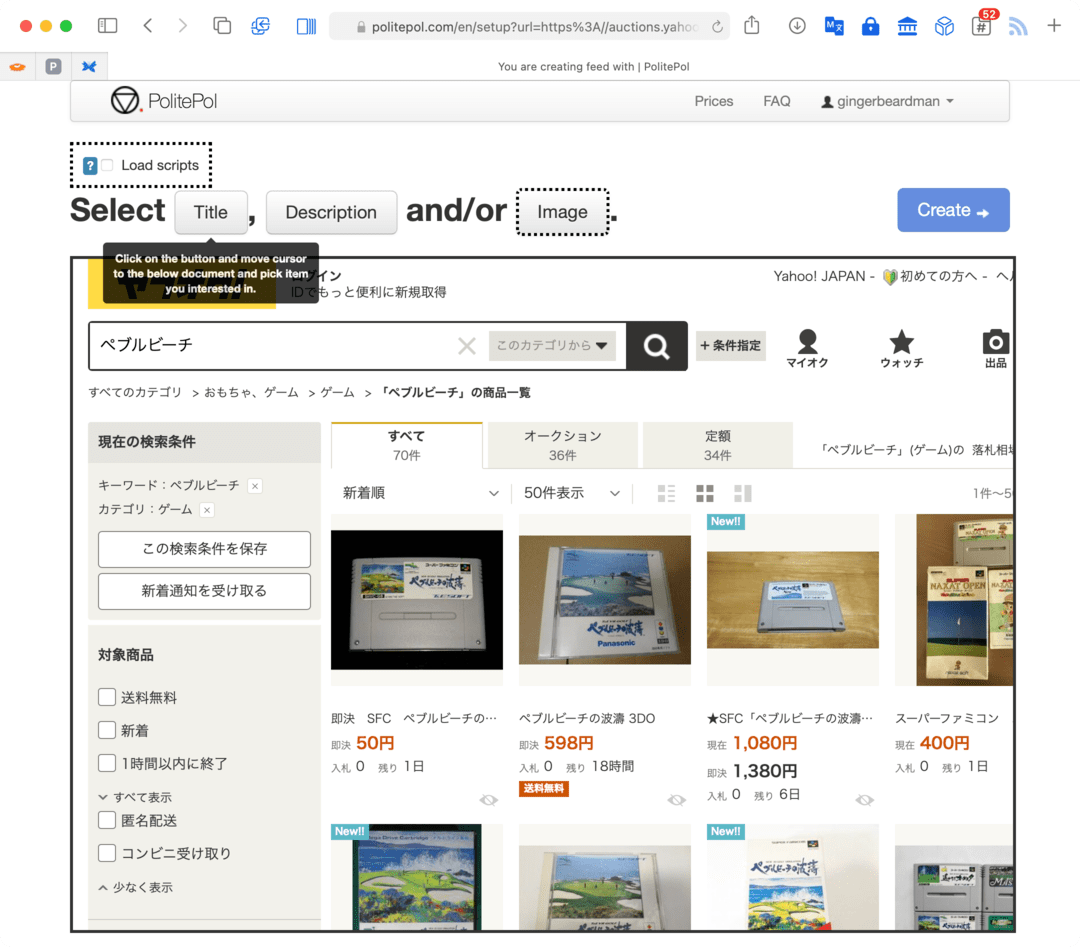
Next, in PolitePol:
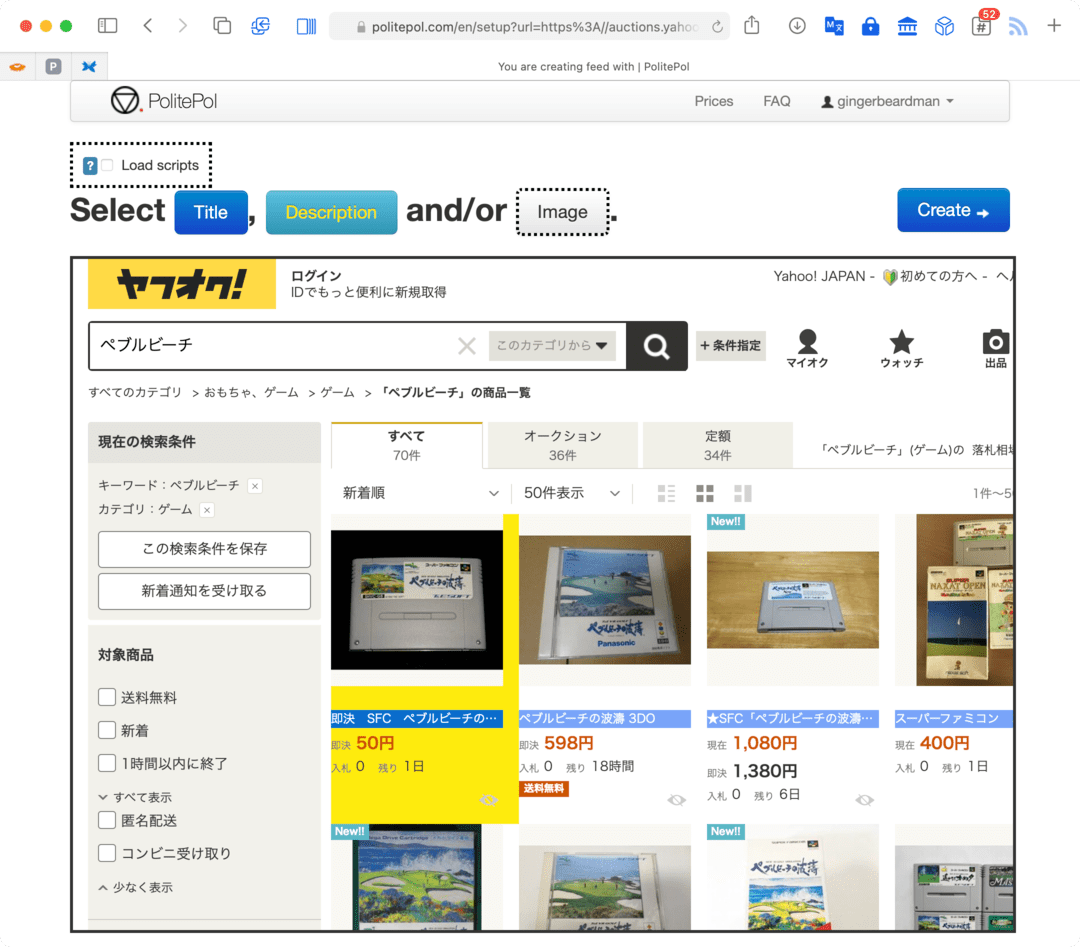
- paste in the URL in and click Go!
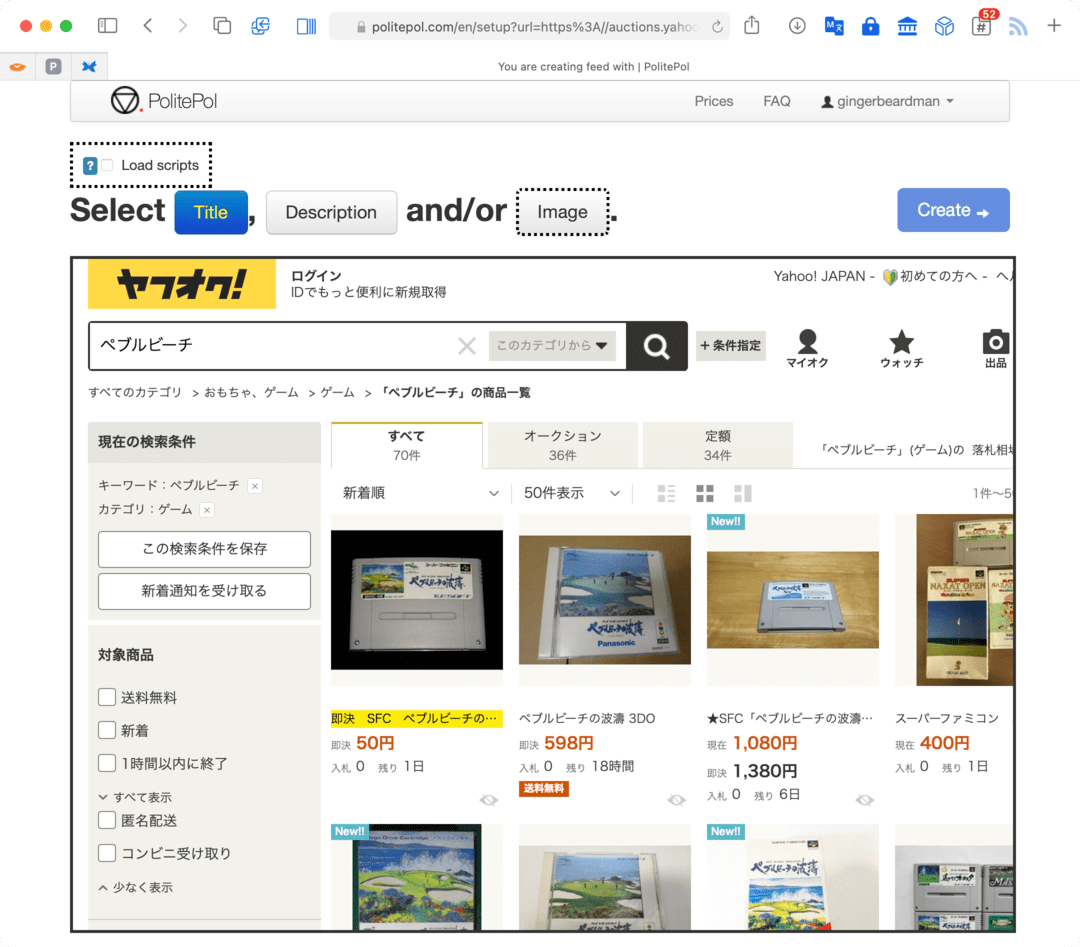
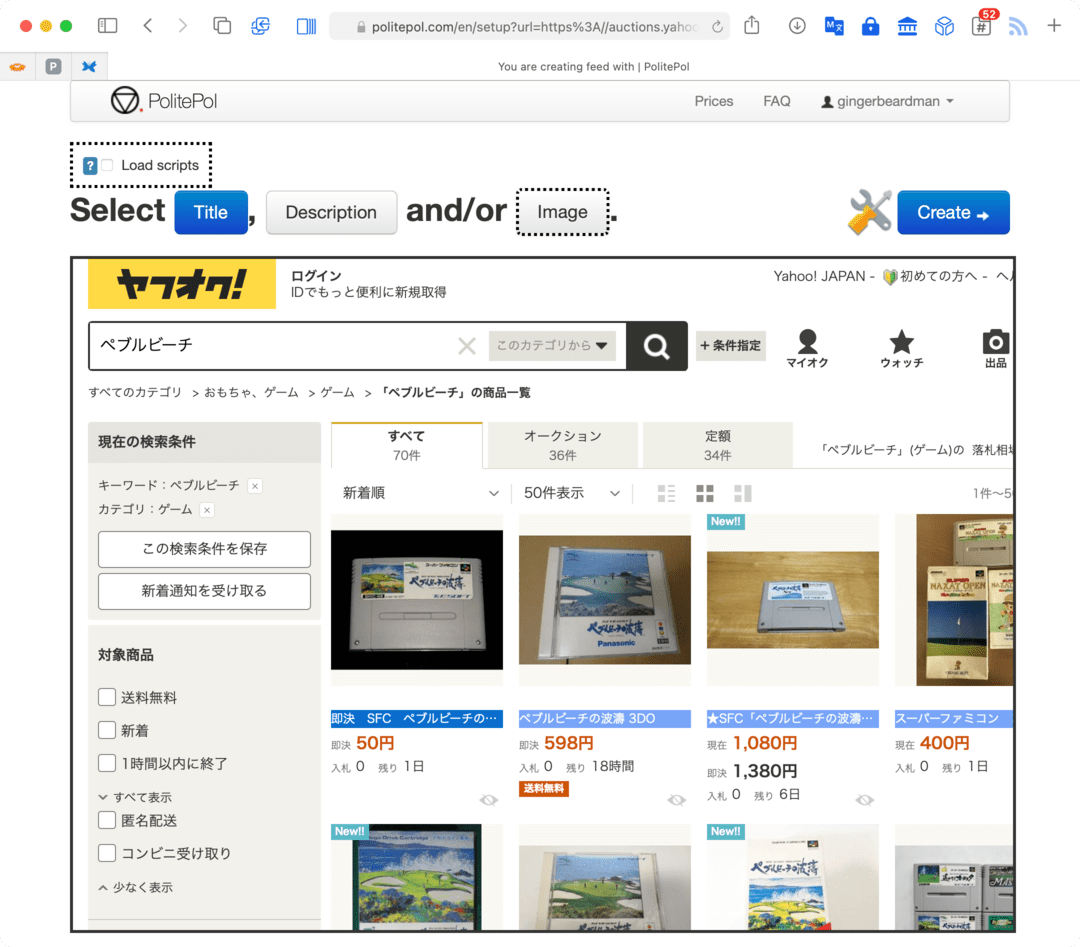
- click the Title button and select the first of any elements you’d like to use as the title (I used the auction name)
- click Description button and select the first of any elements you’d like to use as the description (I used the “table cell”)
But I thought you said no images were allowed?
As previously mentioned a PolitePol free account does not allow selection of images for use in the RSS feed. This is a bit misleading. What it really means: you can not choose an image element to use as the thumbnail/enclosure for each item in the feed.
Whilst it would be nice to have thumbnails in our list of articles, it’s not essential.
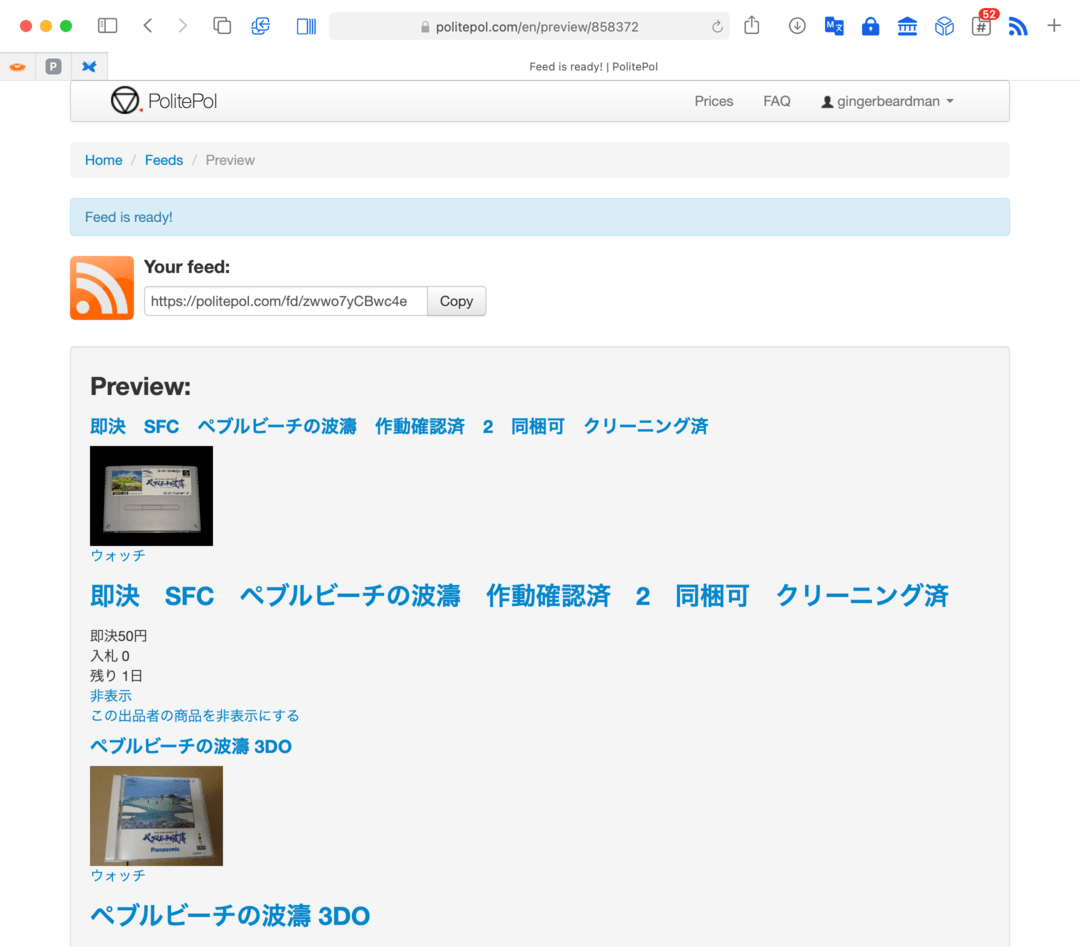
Also, there’s a nice workaround: by selecting the whole table cell as the description we get all of the HTML it contains: its image, title, price, number of bids, remaining time. So we get images in the description anyway. That’ll do nicely!
It’s important to note that the listing details are not live; they are a snapshot taken at the time the feed was refreshed (up to an hour ago with a PolitePol free account).
Here’s the final result in my RSS reader:

It’s up to you
You can use this technique to implement saved searches from any website. Just be sure to check the site doesn’t already have RSS feeds before you begin!
Huginn
Since shortly after this blog post was published I’ve been using Huginn as a replacement for Politepol. There’s no real GUI so you have to scrape using CSS selectors or XPath, but it’s quite a lot more powerful. I’d say it’s a good advanced solution if you run into the limits of Politepol. Here’s an example Huginn Website Agent that scrapes Yahoo! Japan Auctions search results.
Originally published: 2022-01-30
--
Enjoyed this blog post? Please buy me a coffee.
--
Comments: @gingerbeardman